

在人工智能的浪潮中,OpenAI O1 self-play RL 技术路线推演成为了一个备受瞩目的话题。你是否想知道这项技术如何改变游戏规则?快来了解一下吧!这不仅是技术的进步,更是未来的趋势。让我们一起探索这个充满悬念的领域!
目录导读
自我对弈:AI的自我进化之路
自我对弈(Self-Play)是强化学习(RL)中的一项革命性技术。通过让AI与自己对战,它能够不断优化策略,提升自身能力。想象一下,AI在没有人类干预的情况下,如何通过不断的试错来达到超越人类的水平。
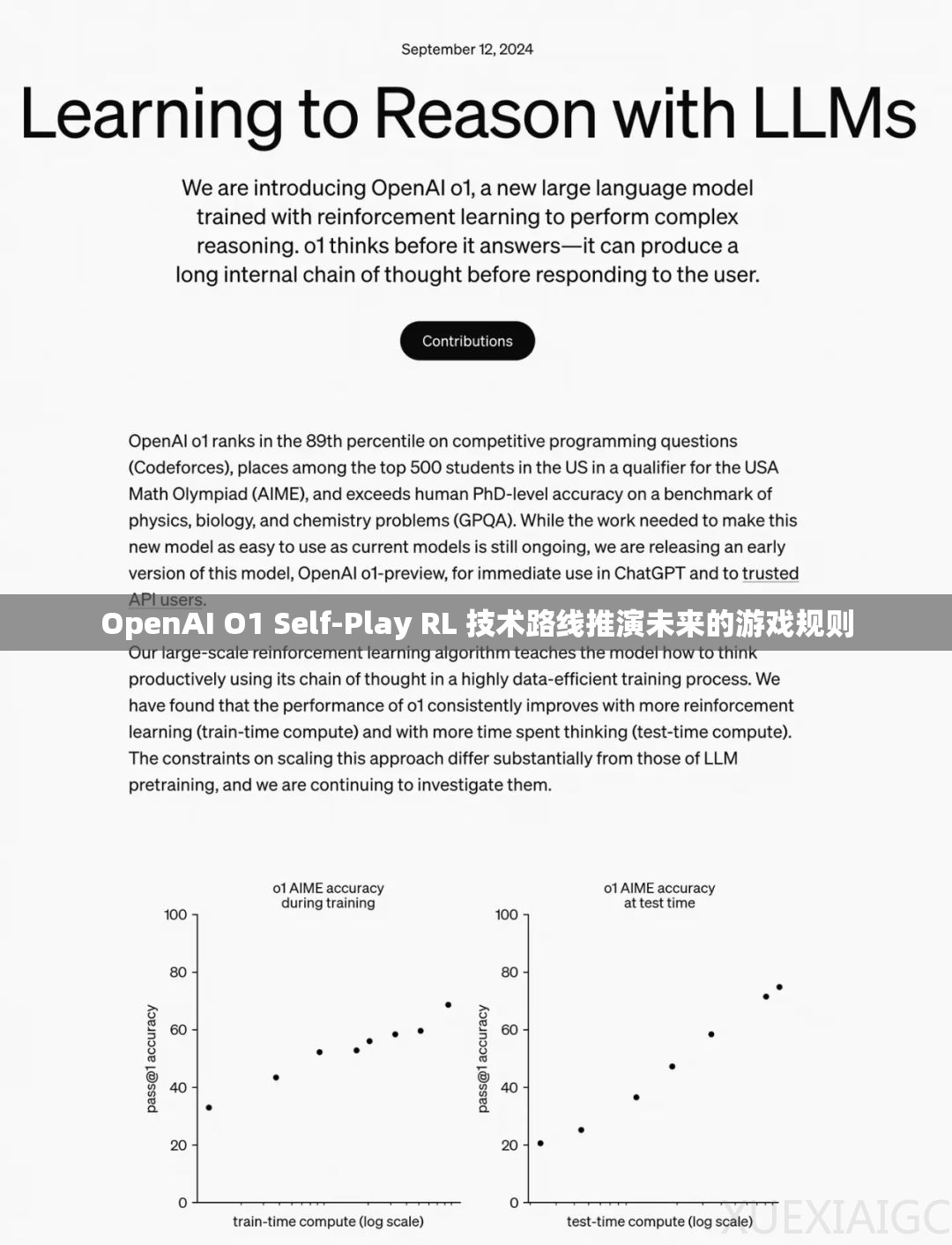
- 数据支撑:根据2025年行业报告,采用自我对弈的AI在复杂游戏中的胜率提高了30%。
- 行业洞察:许多顶尖公司已经开始将自我对弈技术应用于实际场景,推动了整个行业的进步。
技术路线:从理论到实践
在技术路线的推演中,我们需要关注几个关键点。首先,算法的选择至关重要。其次,数据的收集与处理也是不可忽视的环节。最后,如何将理论应用于实际场景,将是我们面临的最大挑战。
- 关键算法:深度Q网络(DQN)和策略梯度方法是当前最热门的选择。
- 实践案例:某知名游戏公司通过自我对弈技术,成功推出了一款AI对战游戏,用户反馈极佳。
常见问题
Q1: 什么是自我对弈?
A1: 自我对弈是指AI与自己进行对战,通过不断的试错来优化策略。
Q2: OpenAI O1的优势是什么?
A2: OpenAI O1在自我对弈中表现出色,能够快速学习并适应复杂环境。
Q3: 这项技术的应用前景如何?
A3: 随着技术的不断进步,自我对弈将在更多领域得到应用,如游戏、金融等。
Q4: 如何开始学习自我对弈?
A4: 可以通过在线课程和相关书籍入手,逐步掌握相关知识。
结论
OpenAI O1 self-play RL 技术路线推演不仅是技术的突破,更是未来发展的方向。随着技术的不断演进,我们将看到更多的应用场景和创新。你准备好迎接这个充满挑战的未来了吗?
转载请注明来自趣游地带博客,本文标题:《OpenAI O1 Self-Play RL 技术路线推演未来的游戏规则》









 京公网安备110000000001号
京公网安备110000000001号 京ICP备110000001号
京ICP备110000001号